Виды поисковых роботов. Что такое поисковый робот? Функции поискового робота "Яндекса" и Google
Из этой статьи вы узнаете все о поисковых системах.
Краткое ведение.
Как робот находит новую информацию?
Процесс индексации.
Принцип работы поисковой системы google.
Как определяется соответствие?
Как поисковые роботы видят сайты?
Что же такое поисковая система? Это такой комплекс, включающий в себя ряд специализированных средств для предоставления информации людям. Говоря человеческим языком – это система, позволяющая буквально любому пользователю найти нужную ему информацию.
Наиболее популярными поисковыми системами являются:
Yandex(Яндекс) – наиболее популярна в странах СНГ. Стоит отметить, что доля данной поисковой системы в РФ, составляет более чем 60%. Она владеет огромной базой данных.
Goolge(Гугл) – в отличии от яндекса, популярная во всем мире.
Предлагаю рассмотреть их более подробно. Располагайтесь поудобнее, начинаем.
Принцип работы поисковой системы Yandex
Для начала, яндекс проводит сбор всей возможной информации, до которой он может добраться. Затем, с помощью специального оборудования контент проходит проверку. Важной особенностью является то, что сбором информации занимается специализированная поисковая машина, а процесс, с помощью которого проходит подготовка данных, называется индексированием.
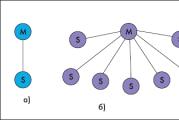
Поисковая машина состоит из поискового робота(вот для чего нужен файлик robots.txt). Он периодически посещает индексированные сайты, проверяет их контент(обновился или нет) и проводит сканирование Интернета на наличие незначимых страниц(пустых или удаленных), если нужно – удаляет их.
Как робот находит новую информацию
Есть три известных способа:С помощью ссылок с других источников.Благодаря специальному сервису «Аддурилке» — добавить новый адрес. В нем можно добавить новый адрес вашего сайта и по истечению некоторого времени его посетит поисковый робот.Используя программный пакет – ЯндексБар. Им отслеживается активность пользователя(какие сайты посещает), который пользуется пакетом и затем если юзер попадает на новый ресурс, то за ним следует и робот
Процесс индексации
С помощью различных поисковых алгоритмов, робот проверяет информацию на соответствие – полезна ли она для пользователя или нет и затем он ее либо добавляет в список либо удаляет.
После определения полезности, информация добавляется в специальное хранилище и разбирается до самых мелких частей. Страничка проходит очистку от хтмл- разметки, затем кристальный текст отправляется на инвентаризацию
Принцип работы поисковой системы Google
Данная система работает с помощью трех базовых для нее шагов:
Процесс сканирования.
Это шаг, на протяжении которого специальные поисковые роботы гугла находят новые, обновленные страницы, чтобы потом добавить их в поисковую базу.
В распоряжении Гугл находится огромное количество мощных компьютеров, предназначенных для сканирования огромного количества страниц.
Специальная программа проводит выборку – Googlebot, который имеет свои алгоритмы – какие и как часто сканировать страницы и количество индексированных страниц.
Сканирование начинается с url – адреса каждой страницы.
Непосредственно индексация
Что это такое? Это процесс, на котором робот Гугл обрабатывает каждую страницу, на которую он заходит, чтобы проанализировать местоположения ключевых слов на каждой страничке.
Также, гугл имеет более расширенный функционал – обрабатывает информацию, которая располагает в таких ключевых тегах, как title и alt.
Минусом бота является то, что он не может обрабатывать страницы, которые имеют множество мультимедийных файлов и динамические страницы.
Этап обработки
Это последний процесс. Он наступает в тот момент, когда пользователь сети вводит нужный ему поисковый запрос. Вот он ввел его, теперь поисковая система сразу же заходит в БД(базу данных) и подбирает наиболее соответствующую ключевому запросу информацию.
Как определяется соответствие
Существует огромное количество факторов, но главным из них является PR(ранг страницы, то есть, это показатель важности страницы и чем он выше, тем лучше).
Увы, далеко не все ссылочки равны, но корпорация Google продуктивно работает над решением этой проблемы – находит спамовые ссылки, проверяет файлик robots.txt, чтобы он не был модифицирован. Важно! Наиболее качественными ссылками является те, которые выданы благодаря качественному контенту.
Если вы хотите, чтобы ваш сайт имел наивысшую степень важности, убедитесь, что робот Гугл правильно и беспрепятственно сканирует и индексирует ваш сайт. Специально разработаны для этого сервисы Гугл для вебмастером, способны предотвратить массу популярных ошибок в продвижении, а также помогут повысить PR рейтинг вашего сайта.
Как поисковые роботы видят сайты?
Поисковые системы видят сайты иначе чем мы с вами. Когда мы люди смотрим на сайт мы видим картинки, тексты, видео, разные таблицы и прочий красивый контент. Короче мы видим его в цвете. А что если мы взглянем, как поисковые системы видят контент своими глазами?
Поисковые машины просто любят текст и игнорируют различные картинки. Картинка будет прочтена если добавлен атрибут alt, текстовая подпись к ней. Роботы в основном видят тексты в формате html. Роботы не любят когда на сайте много разных форм и jawa скрипта, такие страницы игнорируются. Если у вас свой сайт уделяйте больше внимания именно текстовому контенту.
Заключение
Если вы хотите, что бы рейтинг вашего сайта стал выше, оптимизируйте контент, внутреннюю часть сайта, чтобы облегчить работу робота – он хоть и умный, но чем лучше оптимизирована страница, тем правильней индексирует поисковый робот сайт.
Удаление сайта целиком
Чтобы удалить сайт из поисковых систем и запретить всем роботам в дальнейшем его сканировать, разместите в корневом каталоге сервера файл robots.txt следующего содержания:
User-agent: *
Disallow: /
Чтобы удалить сайт только из Google и запретить поисковому роботу Google в дальнейшем его сканировать, разместите в корневом каталоге сервера файл robots.txt со следующим содержанием:
User-agent: Googlebot
Disallow: /
Для каждого порта должен быть создан собственный файл robots.txt. В частности, если используются протоколы http и https, для каждого из них потребуются отдельные файлы robots.txt. Например, чтобы разрешить поисковому роботу Google индексировать все страницы http и запретить сканировать https, файлы robots.txt должны выглядеть следующим образом.
Для протокола http (http://yourserver.com/robots.txt ):
User-agent: *
Allow: /
Для протокола https (https://yourserver.com/robots.txt ):
User-agent: *
Disallow: /
Если файл robots.txt останется в корневом каталоге веб-сервера, в дальнейшем Google не будет сканировать сайт или его каталоги. Если у Вас нет доступа к корневому каталогу сервера, можно поместить файл robots.txt на одном уровне с теми файлами, которые требуется удалить. После того как Вы это сделаете и воспользуетесь системой автоматического удаления URL, сайт будет временно, на 180 дней, удален из индекса Google независимо от того, будет ли удален файл robots.txt после обработки запроса. (Если оставить файл robots.txt на том же уровне, URL потребуется удалять с помощью автоматической системы каждые 180 дней.)
Удаление части сайта
Вариант 1. Robots.txt
Чтобы удалить каталоги или отдельные страницы сайта, можно поместить файл robots.txt в корневом каталоге сервера. О том, как создать файл robots.txt, рассказывается в Стандарт исключений для роботов. Создавая файл robots.txt, учитывайте следующие моменты. Принимая решение о том, какие страницы сканировать на том или ином хосте, поисковый робот Google действует в соответствии с первой записью в файле robots.txt, где параметр User-agent начинается со слова "Googlebot". Если такой записи нет, выполняется первое правило, в котором User-agent – «*». Кроме того, Google позволяет использовать файл robots.txt более гибко за счет применения звездочек. В шаблонах запрета символ «*» может означать любую последовательность символов. Шаблон может оканчиваться символом «$», который обозначает конец имени.
Чтобы удалить все страницы того или иного каталога (например, "lemurs"), добавьте в файл robots.txt такую запись:
User-agent: Googlebot
Disallow: /lemurs
Чтобы удалить все файлы определенного типа (например, .gif), добавьте в файл robots.txt такую запись:
User-agent: Googlebot
Disallow: /*.gif$
Чтобы удалить динамически создаваемые страницы, добавьте в файл robots.txt такую запись:
User-agent: Googlebot
Disallow: /*?
Вариант 2. Мета-теги
Другой стандарт, более удобный для работы со страницами, предусматривает использование на странице формата HTML мета-тега, запрещающего роботам индексировать страницу. Этот стандарт описан на странице .
Чтобы запретить всем роботам индексировать страницу сайта, добавьте в раздел этой страницы следующий мета-тег:
Чтобы запретить индексировать страницу только роботам Google, а остальным разрешить, используйте следующий тег:
Чтобы разрешить роботам индексировать страницу, но запретить переходить по внешним ссылкам, используйте следующий тег:
Примечание. Если Ваш запрос срочный и ждать следующего сканирования Google невозможно, воспользуйтесь автоматической системой удаления URL.. Чтобы запустить этот автоматический процесс, веб-мастер должен сначала вставить в код страницы HTML соответствующие метатеги. После этого каталоги будут временно, на 180 дней, удалены из индекса Google независимо от того, удалите ли Вы файл robots.txt или метатеги после обработки запроса.
Удаление фрагментов (сниппетов)
Фрагмент (сниппет) – это текст, который показывается под названием страницы в списке результатов поиска и описывает содержание страницы.
Чтобы запретить Google выводить фрагменты с Вашей страницы, добавьте в раздел
следующий тег:Примечание. При удалении фрагментов удаляются также и сохраненные в кэше страницы.
Удаление сохраненных в кэше страниц
Google автоматически создает и архивирует снимок каждой сканируемой страницы. Наличие таких сохраненных в кэше версий позволяет конечным пользователям находить страницы, даже если они недоступны (из-за временной неполадки на сервере, где размещена страница). Пользователи видят сохраненные в кэше страницы в том виде, в каком они были в момент сканирования роботом Google. Вверху страницы выводится сообщение о том, что это сохраненная в кэше версия. Чтобы получить доступ к такой странице, пользователь должен выбрать ссылку «Сохранено в кэше» на странице результатов поиска.
Чтобы запретить всем поисковым системам выводить эту ссылку на Ваш сайт, добавьте в раздел
следующий тег:Примечание. Если Ваш запрос срочный и дождаться следующего сеанса сканирования сайта роботом Google невозможно, воспользуйтесь системой автоматического удаления URL. Чтобы запустить этот автоматический процесс, веб-мастер должен сначала вставить в код HTML страницы соответствующие метатеги.
Удаление картинки из системы поиска картинок Google
Чтобы удалить картинку из индекса картинок Google, разместите в корневом каталоге сервера файл robots.txt. (Если это невозможно, поместите его на уровне каталога).
Пример: Если требуется удалить из индекса Google изображение sobaki.jpg, размещенное на Вашем сайте по адресу www.vash-sajt.ru/kartinki/sobaki.jpg, создайте страницу www.vash-sajt.ru/robots.txt и добавьте на нее следующий текст:
User-agent: Googlebot-Image
Disallow: /images/sobaki.jpg
Чтобы удалить из индекса все имеющиеся на сайте картинки, разместите в корневом каталоге сервера файл robots.txt со следующим содержанием:
User-agent: Googlebot-Image
Disallow: /
Это стандартный протокол, который соблюдает большинство сканеров; он позволяет удалить из индекса сервер или каталог. Дополнительная информация о robots.txt представлена на странице
Кроме того, Google позволяет использовать файл robots.txt более гибко за счет использования звездочек. В шаблонах запрета символ «*» может означать любую последовательность символов. Шаблон может оканчиваться символом «$», который обозначает конец имени. Чтобы удалить все файлы определенного типа (например, чтобы оставить картинки в формате.jpg, а в формате.gif удалить), добавьте в файл robots.txt такую запись:
User-agent: Googlebot-Image
Disallow: /*.gif$
Примечание. Если Ваш запрос срочный и дождаться следующего сеанса сканирования сайта роботом Google невозможно, воспользуйтесь системой автоматического удаления URL. Чтобы запустить этот автоматический процесс, веб-мастер должен сначала создать файл robots.txt и поместить его на соответствующем сайте.
Если файл robots.txt останется в корневом каталоге веб-сервера, Google и в дальнейшем не будет сканировать сайт или его каталоги. Если у Вас нет доступа к корневому каталогу сервера, можно поместить файл robots.txt на одном уровне с теми файлами, которые требуется удалить. После того как Вы это сделаете и воспользуетесь системой автоматического удаления URL, временно, на 180 дней, будут удалены каталоги, указанные в файле robots.txt, из индекса Google независимо от того, удалите ли Вы файл robots.txt после обработки запроса. (Если оставить файл robots.txt на том же уровне, URL потребуется удалять с помощью автоматической системы каждые 180 дней.)
Просматривая логи сервера, иногда можно наблюдать чрезмерный интерес к сайтам со стороны поисковых роботов. Если боты полезные (например, индексирующие боты ПС) — остается лишь наблюдать, даже если увеличивается нагрузка на сервер. Но есть еще масса второстепенных роботов, доступ которых к сайту не обязателен. Для себя и для вас, дорогой читатель, я собрал информацию и переделал ее в удобную табличку.
Кто такие поисковые роботы
Поисковый бот , или как еще их называют, робот, краулер, паук — ни что иное, как программа, которая осуществляет поиск и сканирование содержимого сайтов, переходя по ссылкам на страницах. Поисковые роботы есть не только у поисковиков. Например, сервис Ahrefs использует пауков, чтобы улучшить данные по обратным ссылкам, Facebook осуществляет веб-скраппинг кода страниц для отображения репостов ссылок с заголовками, картинкой, описанием. Веб-скраппинг — это сбор информации с различных ресурсов.
Использование имен пауков в robots.txt
Как видим, любой серьезный проект, связанный с поиском контента, имеет своих пауков. И иногда остро стоит задача ограничить доступ некоторым паукам к сайту или его отдельным разделам. Это можно сделать через файл robots.txt в корневой директории сайта. Подробнее про настройку роботса я писал ранее, рекомендую ознакомиться.
Обратите внимание — файл robots.txt и его директивы могут быть проигнорированы поисковыми роботами. Директивы являются лишь рекомендациями для ботов.
Задать директиву для поискового робота можно, используя секцию — обращение к юзер-агенту этого робота. Секции для разных пауков разделяются одной пустой строкой.
User-agent: Googlebot Allow: /
User - agent : Googlebot Allow : / |
Выше приведен пример обращения к основному поисковому роботу Google.
Изначально я планировал добавить в таблицу записи о том, как идентифицируют себя поисковые боты в логах сервера. Но так как для SEO эти данные имеют мало значения и для каждого токена агента может быть несколько видов записей, было решено обойтись только названием ботов и их предназначением.
Поисковые роботы G o o g l e
| User-agent | Функции |
|---|---|
| Googlebot | Основной краулер-индексатор страниц для ПК и оптимизированных для смартфонов |
| Mediapartners-Google | Робот рекламной сети AdSense |
| APIs-Google | Агент пользователя APIs-Google |
| AdsBot-Google | Проверяет качество рекламы на веб-страницах, предназначенных для ПК |
| AdsBot-Google-Mobile | Проверяет качество рекламы на веб-страницах, предназначенных для мобильных устройств |
| Googlebot-Image (Googlebot) | Индексирует изображения на страницах сайта |
| Googlebot-News (Googlebot) | Ищет страницы для добавления в Google Новости |
| Googlebot-Video (Googlebot) | Индексирует видеоматериалы |
| AdsBot-Google-Mobile-Apps | Проверяет качество рекламы в приложениях для устройств Android, работает по тем же принципам, что и обычный AdsBot |
Поисковые роботы Я ндекс
| User-agent | Функции |
|---|---|
| Yandex | При указании данного токена агента в robots.txt, обращение идет ко всем ботам Яндекса |
| YandexBot | Основной индексирующий робот |
| YandexDirect | Скачивает информацию о контенте сайтов-партнеров РСЯ |
| YandexImages | Индексирует изображения сайтов |
| YandexMetrika | Робот Яндекс.Метрики |
| YandexMobileBot | Скачивает документы для анализа на наличие верстки под мобильные устройства |
| YandexMedia | Робот, индексирующий мультимедийные данные |
| YandexNews | Индексатор Яндекс.Новостей |
| YandexPagechecker | Валидатор микроразметки |
| YandexMarket | Робот Яндекс.Маркета; |
| YandexCalenda | Робот Яндекс.Календаря |
| YandexDirectDyn | Генерирует динамические баннеры (Директ) |
| YaDirectFetcher | Скачивает страницы с рекламными объявлениями для проверки их доступности и уточнения тематики (РСЯ) |
| YandexAccessibilityBot | Cкачивает страницы для проверки их доступности пользователям |
| YandexScreenshotBot | Делает снимок (скриншот) страницы |
| YandexVideoParser | Паук сервиса Яндекс.Видео |
| YandexSearchShop | Скачивает YML-файлы каталогов товаров |
| YandexOntoDBAPI | Робот объектного ответа, скачивающий динамические данные |
Другие популярные поисковые боты
| User-agent | Функции |
|---|---|
| Baiduspider | Спайдер китайского поисковика Baidu |
| Cliqzbot | Робот анонимной поисковой системы Cliqz |
| AhrefsBot | Поисковый бот сервиса Ahrefs (ссылочный анализ) |
| Genieo | Робот сервиса Genieo |
| Bingbot | Краулер поисковой системы Bing |
| Slurp | Краулер поисковой системы Yahoo |
| DuckDuckBot | Веб-краулер ПС DuckDuckGo |
| facebot | Робот Facebook для веб-краулинга |
| WebAlta (WebAlta Crawler/2.0) | Поисковый краулер ПС WebAlta |
| BomboraBot | Сканирует страницы, задействованные в проекте Bombora |
| CCBot | Краулер на основе Nutch, который использует проект Apache Hadoop |
| MSNBot | Бот ПС MSN |
| Mail.Ru | Краулер поисковой системы Mail.Ru |
| ia_archiver | Скраппит данные для сервиса Alexa |
| Teoma | Бот сервиса Ask |
Поисковых ботов очень много, я отобрал только самых популярных и известных. Если есть боты, с которыми вы сталкивались по причине агрессивного и настойчивого сканирования сайтов, прошу в комментариях указать это, я добавлю их также в таблицу.
Для сканирования веб-сайтов поисковые системы используют роботов (пауков, краулеров) - программы для индексации страниц и занесения полученной информации в базу данных. Принцип действия паука похож на работу браузера: он оценивает содержимое страницы, сохраняет ее на сервере поисковика и переходит по гиперссылкам в другие разделы.
Разработчики поисковых систем могут ограничивать максимальный объем сканируемого текста и глубину проникновения робота внутрь ресурса. Поэтому для эффективной раскрутки сайта эти параметры корректируют в соответствии с особенностями индексации страниц различными пауками.
Частота визитов, порядок обхода сайтов и критерии определения релевантности информации запросам пользователей задаются поисковыми алгоритмами. Если на продвигаемый ресурс ведет хотя бы одна ссылка с другого веб-сайта, роботы со временем его проиндексируют (чем больше вес линка, тем быстрее). В обратном случае для ускорения раскрутки сайта его URL добавляют в базу данных поисковых систем вручную.
Виды пауков
В зависимости от назначения различают следующие виды поисковых роботов.
- национальные, или главные. Собирают информацию с одного национального домена, например, .ru или.su, и принятых к индексации сайтов;
- глобальные. Осуществляют сбор данных со всех национальных сайтов;
- индексаторы картинок, аудио и видео файлов;
- зеркальщики. Определяют зеркала ресурсов;
- ссылочные. Подсчитывают число ссылок на сайте;
- подсветчики. Оформляют результаты поисковых систем, например, выделяют в тексте запрашиваемые словосочетания;
- проверяющие. Контролируют наличие ресурса в базе данных поисковика и число проиндексированных документов;
- стукачи (или дятлы). Периодически определяют доступность сайта, страницы или документа, на который ведет ссылка;
- шпионы. Выполняют поиск ссылок на ресурсы, еще не проиндексированные поисковыми системами;
- смотрители. Запускаются в ручном режиме и перепроверяют полученные результаты;
- исследователи. Используются для отладки поисковых алгоритмов и изучения отдельных сайтов;
- быстрые роботы. В автоматическом режиме проверяют дату последнего обновления и оперативно индексируют новую информацию.
Обозначения
При поисковой оптимизации сайта часть контента закрывают от индексации роботами (личную переписку посетителей, корзины заказов, страницы с профилями зарегистрированных пользователей и т.д.). Для этого в файле robots.txt в поле User-agent прописывают имена роботов: для поисковой системы Яндекс — Yandex, для Google - Googlebot, для Rambler - StackRambler, для Yahoo - Yahoo! Slurp или Slurp, для MSN - MSNBot, для Alexa - ia_archiver и т.д.
Иногда роботы могут маскироваться под роботов Яндекса путем указания соответствующего User-agent. Вы можете проверить, что робот является тем, за кого себя выдает используя идентификацию, основанную на обратных DNS-запросах (reverse DNS lookup).
Для этого необходимо выполнить следующее:
Удостоверьтесь в корректности полученного имени. Для этого нужно использовать прямой DNS-запрос (forward DNS lookup), чтобы получить IP-адрес, соответствующий имени хоста. Он должен совпадать с IP-адресом, использованным при обратном DNS запросе. Если IP-адреса не совпадают, это означает, что полученное имя хоста поддельное.
- Вопросы и ответы
По IP-адресу определите доменное имя хоста с помощью обратного DNS-запрос.
Проверьте, принадлежит ли хост Яндексу. Имена всех роботов Яндекса заканчиваются на сайт , yandex.net или yandex.com . Если имя хоста имеет другое окончание, это означает, что робот не принадлежит Яндексу.
Роботы Яндекса в логах сервера
Некоторые роботы Яндекса скачивают документы не для их последующей индексации, а для других специфичных целей. Для избежания непреднамеренной блокировки владельцами сайтов они могут не учитывать ограничивающие директивы файла robots.txt , предназначенным для произвольных роботов (User-agent: * ).
Также частичное игнорирование ограничений robots.txt определенных сайтов возможно при наличии соответствующей договоренности между компанией «Яндекс» и владельцами этих сайтов.
Примечание. Если такой робот скачает документ, не доступный основному роботу Яндекса, этот документ никогда не будет проиндексирован и не попадет в поисковую выдачу.
Чтобы ограничить доступ таких роботов к сайту, используйте директивы специально для них, например:
User-agent: YandexCalendar\nDisallow: /\n\nUser-agent: YandexMobileBot\nDisallow: /private/*.txt$
Роботы используют множество IP-адресов, которые часто меняются. Поэтому их список не разглашается.
| Полное имя робота, включая User agent | Назначение робота | Учитывает общие правила, указанные в robots.txt |
|---|---|---|
| Mozilla/5.0 (compatible; YandexAccessibilityBot/3.0; +http://yandex.com/bots) | Скачивает страницы для проверки их доступности пользователям. Его максимальная частота обращений к сайту составляет 3 обращения в секунду. Робот игнорирует и директиву Crawl-delay . | Нет |
| Mozilla/5.0 (compatible; YandexAdNet/1.0; +http://yandex.com/bots) | Робот Рекламной сети Яндекса . | Да |
| Mozilla/5.0 (compatible; YandexBlogs/0.99; robot; +http://yandex.com/bots) | Робот поиска по блогам , индексирующий комментарии постов. | Да |
| Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots) | Основной индексирующий робот. | Да |
| Mozilla/5.0 (compatible; YandexBot/3.0; MirrorDetector; +http://yandex.com/bots) | Определяющий зеркала сайтов. | Да |
| Mozilla/5.0 (compatible; YandexCalendar/1.0; +http://yandex.com/bots) | Робот Яндекс.Календаря . Скачивает файлы календарей по инициативе пользователей, которые часто располагаются в запрещенных для индексации каталогах. | Нет |
| Mozilla/5.0 (compatible; YandexCatalog/3.0; +http://yandex.com/bots) | Используется для временного снятия с публикации недоступных сайтов в Яндекс.Каталоге . | Да |
| Mozilla/5.0 (compatible; YandexDirect/3.0; +http://yandex.com/bots) | Скачивает информацию о контенте сайтов-партнеров Рекламной сети Яндекса, чтобы уточнить их тематику для подбора релевантной рекламы. | Нет |
| Mozilla/5.0 (compatible; YandexDirectDyn/1.0; +http://yandex.com/bots | Генерирует динамические баннеры. | Нет |
| Mozilla/5.0 (compatible; YandexFavicons/1.0; +http://yandex.com/bots) | Скачивает файл фавиконки сайта для отображения в результатах поиска. | Нет |
| Mozilla/5.0 (compatible; YaDirectFetcher/1.0; Dyatel; +http://yandex.com/bots) | Скачивает целевые страницы рекламных объявлений для проверки их доступности и уточнения тематики. Это необходимо для размещения объявлений в поисковой выдаче и на сайтах-партнерах. | Нет. Робот не использует файл robots.txt |
| Mozilla/5.0 (compatible; YandexForDomain/1.0; +http://yandex.com/bots) | Робот почты для домена , используется при проверке прав на владение доменом. | Да |
| Mozilla/5.0 (compatible; YandexImages/3.0; +http://yandex.com/bots) | Индексирует изображения для показа на Яндекс.Картинках . | Да |
| Mozilla/5.0 (compatible; YandexImageResizer/2.0; +http://yandex.com/bots) | Робот мобильных сервисов. | Да |
| Mozilla/5.0 (iPhone; CPU iPhone OS 8_1 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Version/8.0 Mobile/12B411 Safari/600.1.4 (compatible; YandexBot/3.0; +http://yandex.com/bots) | Индексирующий робот. | Да |
| Mozilla/5.0 (iPhone; CPU iPhone OS 8_1 like Mac OS X) AppleWebKit/600.1.4 (KHTML, like Gecko) Version/8.0 Mobile/12B411 Safari/600.1.4 (compatible; YandexMobileBot/3.0; +http://yandex.com/bots) | Определяет страницы с версткой, подходящей под мобильные устройства. | Нет |
| Mozilla/5.0 (compatible; YandexMarket/1.0; +http://yandex.com/bots) | Робот Яндекс.Маркета . | Да |
| Mozilla/5.0 (compatible; YandexMedia/3.0; +http://yandex.com/bots) | Индексирует мультимедийные данные. | Да |
| Mozilla/5.0 (compatible; YandexMetrika/2.0; +http://yandex.com/bots) | Робот Яндекс.Метрики | Нет |
| Mozilla/5.0 (compatible; YandexMetrika/4.0; +http://yandex.com/bots) | Робот Яндекс.Метрики . Скачивает и кэширует CSS-стили для воспроизведения страниц сайта в Вебвизоре . | Нет. Робот не использует файл robots.txt , поэтому игнорирует директивы, установленные для него. |
| Mozilla/5.0 (compatible; YandexMetrika/2.0; +http://yandex.com/bots yabs01) | Скачивает страницы сайта для проверки их доступности, в том числе проверяет целевые страницы объявлений Яндекс.Директа. | Нет. Робот не использует файл robots.txt , поэтому игнорирует директивы, установленные для него. |
| Mozilla/5.0 (compatible; YandexNews/4.0; +http://yandex.com/bots) | Робот Яндекс.Новостей | Да |
| Mozilla/5.0 (compatible; YandexOntoDB/1.0; +http://yandex.com/bots) | Робот объектного ответа . | Да |
| Mozilla/5.0 (compatible; YandexOntoDBAPI/1.0; +http://yandex.com/bots) | Робот объектного ответа , скачивающий динамические данные. | Нет |
| Mozilla/5.0 (compatible; YandexPagechecker/1.0; +http://yandex.com/bots) | Обращается к странице при валидации микроразметки через форму Валидатор микроразметки . | Да |
| Mozilla/5.0 (compatible; YandexSearchShop/1.0; +http://yandex.com/bots) | Скачивает YML-файлы каталогов товаров (по инициативе пользователей), которые часто располагаются в запрещенных для индексации каталогах. | Нет |
| Mozilla/5.0 (compatible; YandexSitelinks; Dyatel; +http://yandex.com/bots) | Проверяет доступность страниц, которые используются в качестве быстрых ссылок . | Да |
| Mozilla/5.0 (compatible; YandexSpravBot/1.0; +http://yandex.com/bots) | Робот Яндекс.Справочника . | Да |
| Mozilla/5.0 (compatible; YandexTurbo/1.0; +http://yandex.com/bots) | Обходит RSS-канал, созданный для формирования Турбо-страниц . Его максимальная частота обращений к сайту составляет 3 обращения в секунду. Робот игнорирует настройку в интерфейсе Яндекс.Вебмастера и директиву Crawl-delay . | Да |
| Mozilla/5.0 (compatible; YandexVertis/3.0; +http://yandex.com/bots) | Робот поисковых вертикалей. | Да |
| Mozilla/5.0 (compatible; YandexVerticals/1.0; +http://yandex.com/bots) | Робот Яндекс.Вертикалей: Авто.ру , Янекс.Недвижимость , Яндекс.Работа , Яндекс.Отзывы. | Да |
| Mozilla/5.0 (compatible; YandexVideo/3.0; +http://yandex.com/bots) | Яндекс.Видео . | Да |
| Mozilla/5.0 (compatible; YandexVideoParser/1.0; +http://yandex.com/bots) | Индексирует видео для показа на |